
Tutorial RAG com NextJS
Introdução
Nesse tutorial, vou falar um pouco mais sobre essa poderosa ténica de AI conhecida como RAG: Retrieval-Augmented Generation.
Para tornar as coisas mais palatáveis, vamos construir um projetinho prático aplicando a téncica. Espero assim que você consiga, ao final desse conteúdo, entender como ela pode ser aplicada em suas soluções, especialmente no contexto de projetos React e Typescript.
O que é RAG
RAG, ou Retrieval-Augmented Generation, é uma técnica de aprendizado de máquina que combina duas abordagens principais: recuperação de informações e geração de texto.
Essencialmente, a RAG busca por informações relevantes em um grande conjunto de dados e usa essas informações para gerar respostas úteis e detalhadas.
Confuso ainda? Deixa eu te ajudar…
RAG é uma ferramente bastante útil para lidar com uma das grandes limitações das LLMs: o limite de tokens.
A cada mensagem que você troca com o ChatGPT, por exemplo, há um limite de tokens (palavras, para simplificar) que você pode enviar (e o GPT pode responder).
Imagine que você quisesse, por exemplo, pedir para o GPT te dar respostas a partir do conteúdo de um livro.
Parece simples, não? Basta copiar todo o conteúdo do livro, colar no chat, e, em seguida, fazer a pergunta.
Mas por conta da limitação de janela de contexto, isso não é possível.
Até há novos modelos como o Gemini Pro que promete ser capaz de ter janelas de contexto de mais de 1 milhão de tokens (dá para enviar o Senhor dos Aneis e fazer perguntas sobre ele).
Mas mesmo assim, tais modelos provavelmente serão bastante caros. Imagina ter que transferir tanto dado (e pagar por todos esses tokens) a cada pergunta?
Logo, temos que achar um alternativa com os modelos mais baratos, capaz de aceitar apenas alguns milhares de tokens (o gpt 3, por exemplo, é capaz de aceitar no máximo 16 mil tokens – o que dá umas 12 ou 13 mil palavras).
É aí que a RAG entre em cena.
Podemos rapidamente, utilizando a técnica, achar os trechos mais relevantes do texto de um livro, por exemplo, e injetar esse conteúdo junto com a nossa questão em um prompt, e perguntar a uma LLM.
Desta forma, a LLM vai dar uma resposta bastante precisa para sua pergunta, mesmo que ela tenha sido feita sobre o conteúdo de um livro com milhares de páginas. Tudo isso de uma forma econômica e rápida.
Breve introdução do projeto que iremos fazer
Vamos criar uma simples API route em um projeto Nextjs, quer irá permitir que o usuário envie um texto (sobre o qual ele deseja fazer perguntas), e a própria pergunta.
Por exemplo: digamos que o usuário quisesse saber respostas bem específicas sobre o BBB24, com base no conteúdo disponível sobre o reality na Wikipedia.
Neste projeto, seria possível mandarmos em uma requisição POST, em seu body, a questão, e também o conteúdo em texto do artigo.
A ideia é que possamos ter então respostas precisas usando RAG.
Dependências
Para isso, precisamos criar um projeto nextjs, além de instalar as seguintes dependências:
npm install langchain @langchain/openaiAlém disso, você também vai precisar criar uma API Key na OpenAI.
Uma vez criada, basta salvá-la em um arquivo .env.local com o seguinte nome:
OPENAI_API_KEY='sk-xxxxxx....'Indo para o código
Vamos criar algumas funções para organizar melhor o nosso código:
A função splitSourceTextToChunks usa a classe RecursiveCharacterTextSplitter para dividir o texto de referência em partes de um tamanho específico.
A função createEmbeddings usa a classe OpenAIEmbeddings para criar “embeddings” (transformar os chunks do texto de referência em vetores, paara podermos fazer busca semântica) para cada parte do texto.
A função queryRetriever usa a classe MemoryVectorStore para buscar as partes mais relevantes do texto com base na pergunta.
A função queryText usa a classe ChatOpenAI para gerar uma resposta com base nas partes relevantes do texto e na pergunta.
O código completo
O código final vai ficar desse jeito:
// npm install langchain @langchain/openai
export const useCaseRagTalkToText = async (
sourceText: string,
question: string
): Promise => {
const chunks = await splitSourceTextToChunks(sourceText);
const vectorStore = await createEmbeddings(chunks);
const result = await queryRetriever(vectorStore, question);
const rawResponse = await queryText(
question,
result.map((data) => data.pageContent)
);
return {
chunks,
vectorStore,
result,
rawResponse,
response: rawResponse.lc_kwargs["content"],
};
};
// TEXT CHUNKING
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
const splitSourceTextToChunks = async (sourceText: string) => {
const CHUNK_SIZE_CHARS = 500;
const CHUNK_OVERLAP = CHUNK_SIZE_CHARS * 0.2;
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: CHUNK_SIZE_CHARS,
chunkOverlap: CHUNK_OVERLAP,
});
const chunks = await textSplitter.splitText(sourceText);
return chunks;
};
// CREATE EMBEDDINGS
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { OpenAIEmbeddings } from "@langchain/openai";
const createEmbeddings = async (textChunks: string[]) => {
const openAIEmbeddings = new OpenAIEmbeddings();
// metadata to be associated with each chunk
const chunksMetaDataIds = textChunks.map((_, index) => index);
const vectorStore = await MemoryVectorStore.fromTexts(
textChunks,
chunksMetaDataIds,
openAIEmbeddings
);
return vectorStore;
};
// QUERY RETRIEVER
const queryRetriever = async (
vectorStore: MemoryVectorStore,
query: string
) => {
const RESPONSE_CHUNKS = 3;
const retriever = vectorStore.asRetriever({
k: RESPONSE_CHUNKS,
searchType: "similarity",
});
const results = await retriever.invoke(query, {});
return results;
};
const getPrompt = (question: string, context: string[]) => {
const prompt = You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise. Question: ${question} Context: ${context.join(";")} Answer: ;
return prompt;
};
// QUERY TEXT
import { ChatOpenAI } from "@langchain/openai";
const queryText = async (question: string, context: string[]) => {
const llm = new ChatOpenAI({
model: "gpt-3.5-turbo",
temperature: 0.3,
});
const prompt = getPrompt(question, context);
const response = await llm.invoke(prompt);
return response;
};Agora, basta ir na api route que você definiu e chamar o use case, desta forma:
import { useCaseRagTalkToText } from "@/apps/rag";
import type { NextApiRequest, NextApiResponse } from "next";
export default async function handler(
req: NextApiRequest,
res: NextApiResponse
) {
try {
const response = await useCaseRagTalkToText(
req.body.source_text,
req.body.question
);
return res.status(200).json({ response });
} catch (e: any) {
return res.status(200).json({ error: e.message });
}
}
Usando a RAG
Agora, usando Insomnia, vamos fazer nossa primeira questão, mandando também o texto de referência:
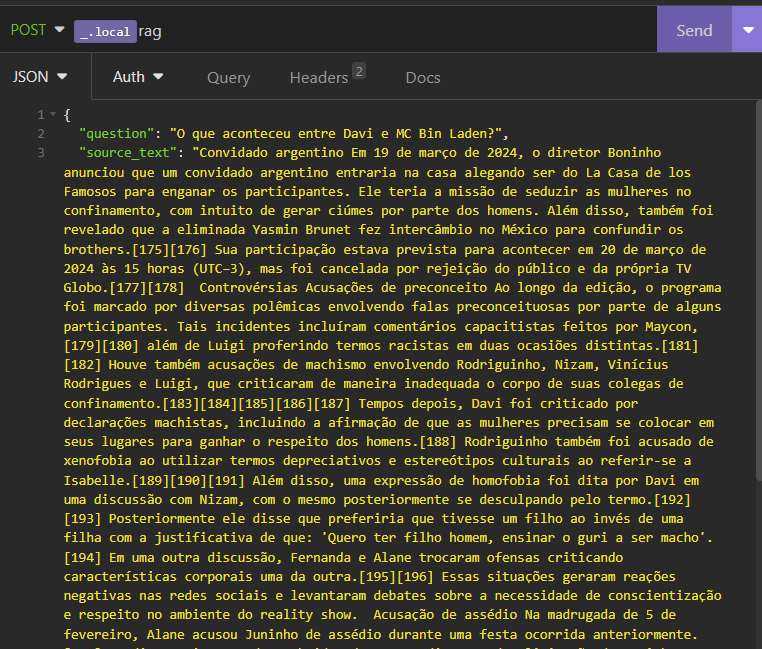
No corpo da requisição, passei um texto do Wikipedia do artigo sobre o reality BBB24. Também enviei uma pergunta que sei que a respostas está contida no texto. Perceba que, por se tratar de fatos recentes à publicação deste artigo, o chatgpt não foi treinado com essas informações. Logo, fazer a mesma pergunta para um chatGPT sem rag resultaria em uma resposta totalmente alucinada.
Como resposta, ao final do body, obtemos o seguinte:

Ao buscarmos no texto, percebemos que isso foi de fato o que aconteceu:

Espero que esse tutorial tenha sido útil para você entender o que é a RAG e como ela pode ser usada em seus projetos React e Typescript. Até a próxima!